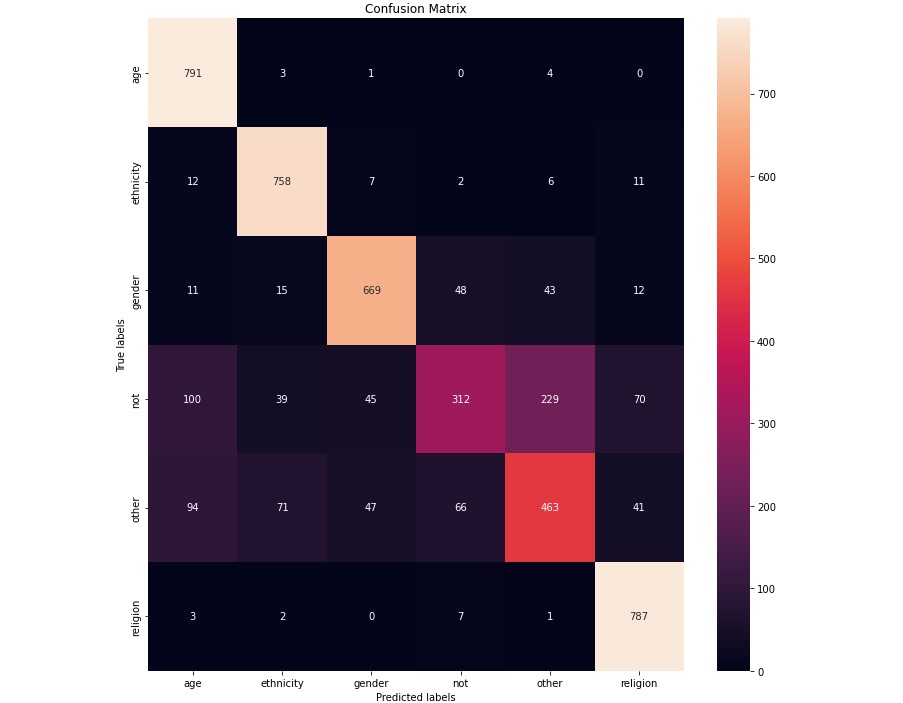
I have created a Naive Bayes classifier based on a dataset of almost 50,000 tweets. This dataset is pre-categorized into 5 categories of cyberbullying and 1 category of not bullying. This classifier relies heavily on data cleaning to prepare the tweets to be categorized. In the data cleaning process, I convert all letters to lowercase and remove all non-alphanumeric characters. I then used NLTK (Natural Language Toolkit) to reduce words to their base form with lemmatization and remove stop words (common words in the language). This essentially reduces the number of unique words by removing unnecessary words and combining many similar words into their bases. I also use Laplace smoothing in the classification step.
At the end, I am able to improve the initial Naive Bayes base classifier from around a 49% success to a 79.2% success rate. Check the GitHub repository for more information on technical steps and areas that can be improved upon in the future.